(三) 查询执行
1. 前言
查询处理器 是 DBMS 中的一个部件集合,它能够将用户的查询和数据修改的命令转变为数据库上的操作序列并且执行这些操作。
Figure 1: 查询处理器的主要部分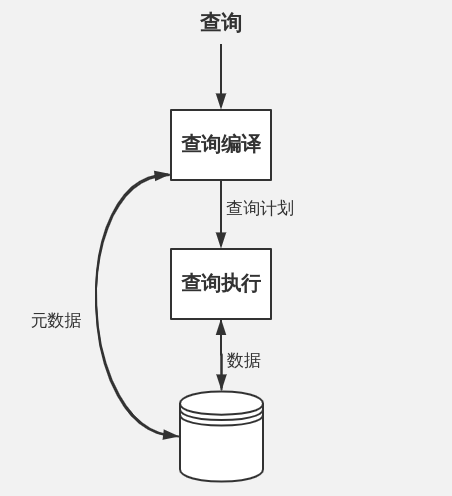
1.1 查询编译预览
查询编译可以分为三大步骤:
- 分析
- 建立查询的分析树
- 查询重写
- 分析树被转化为
初始查询计划,这种查询计划通常是查询的代数表达方式。然后初始查询计划被转化为一个预期所需执行时间较小的等价计划。 - 物理计划生成
- 通过 查询重写 中抽象的查询计划,即通常所谓
逻辑查询计划的每一个操作符选择实现的算法并选择这些操作符的执行顺序,逻辑计划被转换为物理查询计划。与分析结果和逻辑计划一样,物理计划用表达式树来表示。物理计划还包含许多细节,如被查询的关系是怎样被访问的,以及一个关系何时或是应当被排序。
查询重写 和 物理计划生成 部分常被称作 查询优化器 ,他们是查询编译的难点。为了选择最好的查询计划,我们需要判断:
- 查询的哪一个代数等价形式会为回答查询带来最有效的算法?
- 对选中的形式的每一个操作,我们应当使用什么算法来实现?
- 数据如何从一个操作传到另一个操作,比如流水线方式,主存缓存区还是通过磁盘?
这些选择中的每一个都依赖于数据库的元数据。查询优化可利用的典型的元数据包括: 每个关系的大小 , 统计数据 (比如一个属性的不同值的近似数目和频率,某些索引的存在,以及数据在磁盘上的分布)
Figure 2: 查询编译概貌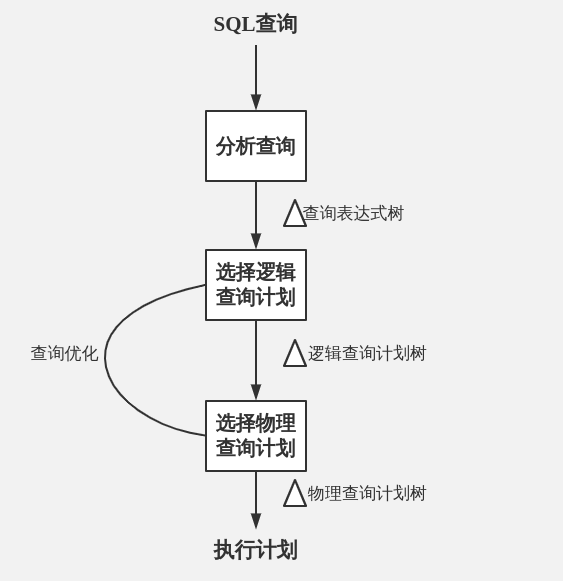
2. 物理查询计划操作符介绍
物理查询计划 由操作符构成,每一个操作符实现计划中的一步。物理操作符常常是一个 关系代数操作符 的特定的实现。但是,我们也需要物理操作符来完成与另一些和关系代数操作符无关的任务。譬如,我们经常需要”扫描”一个表,即将作为关系代数表达式的操作对象的某个关系的每个元组调入内存。这个关系是对某个其他的操作的典型操作数。
2.1 扫描表
我们在一个物理查询计划中可能可以做的最基本事情就是读一个关系$R$的整个内容。这个操作符的一个 variation 包含了一个简单的 predictate ,需要我们只读出关系$R$中满足这个 predictate 的元组。这里有两种途径来定位关系 \(R\) 中的元组:
- 在很多种情况下,关系 \(R\) 存放在二级存储器的某个区域中,它的元组排放在块中。系统知道包含 \(R\) 的元组的块,并且可以一个接一个得到这些快。这个操作叫做
表-扫描(table-scan) - 如果 \(R\) 的任意一个属性上有索引,我们可以使用这个索引来得到 \(R\) 的所有元组。比如, \(R\) 上的稀疏索引,可以用来指引我们得到所有的包含 \(R\) 的块,即使我们就不知道这些块是哪些。这个操作叫
索引-扫描(index-scan)
我们使用索引不只是获取它索引关系的所有元组,而是去获取
那些构成索引搜索 key的属性 或属性中具有特定值(有时是特定范围的值)的元组
2.2 扫描表时排序
当我们读一个关系的元组时,有很多原因促使我们将关系排序。举个例子,其中一个查询可能包含一个 ORDER BY 子句,要求对关系排序。另一个例子, 一些实现了关系代数运算的方法要求一个或全部参数是排序关系。
物理查询计划操作符 排序-扫描 接受关系 \(R\) 和 要求对哪个属性进行排序的说明 ,并产生排好顺序的 \(R\) 。实现 排序-扫描 的方法有很多种。如果关系 \(R\) 必须按照属性 \(a\) 排好序,并且在 \(a\) 上有一个 b-tree 索引,那么扫描索引允许我们以想要的顺序产生 \(R\) 。如果 \(R\) 小到能装进内存,那我们可以使用 表-扫描 或 索引-扫描 来得到它的元组,然后使用主存排序算法。如果 \(R\) 太大以至于内存装不下,那么 多路归并方法 是一个不错的选择
2.3 物理操作符计算模型
一个查询通常包含几个 关系代数 操作,相应的 物理查询计划 由几个 物理操作符 组成。因为明智的选择 物理计划操作符 是良好的 查询处理器 的必要条件,所以我们必须能够估算我们使用每个操作符的”代价”。我们将使用磁盘 \(I/O\) 的数目作为衡量每个操作的代价的标准。这个衡量标准与我们前面的一个观点是一致的: 从磁盘中得到的数据时间比对内存中的数据做任何有用操作所花费的时间都要长 。
2.4 衡量代价的参数
现在,让我们引入用于表达一个操作符代价的参数(有时也被称为统计数据)。如果优化器打算确定许多查询计划中的哪一个执行最快,那么估算代价是必需的。
我们需要一个参数来表达操作符使用的内存大小,我们还需要其他参数来衡量它的操作对象的大小。假设内存被分为缓冲区,缓冲区的大小与磁盘块大小相同。那么 \(M\) 表示一个特定的操作符执行时可以获得的内存缓冲区的数目 。有时候,我们可以认为 \(M\) 是整个内存或内存的绝大部分。事实上,一个操作可得到的缓冲区的数目可能不是一个可以预计的常数,而可能在执行过程中根据同时执行的其他进程决定。如果是这样,$M$实际上是对一个操作可得到的缓冲区数目的估计。
接下来,让我们来考虑衡量与访问相关的关系所需代价的参数。这些衡量关系中数据的多少和分布的参数经常被定期的计算,以便帮助查询优化器选择物理操作符。
我们将做一个简化的假设,即在磁盘上一次访问一个块的数据。实际上,如果我们能够一次读一个关系的许多块,这些块可能来自一个磁道上连续的块。有三类参数 \(B\) 、 \(T\) 、和 \(V\) :
- 当描述一个关系 \(R\) 的大小时,绝大多数情况下,我们关心包含 \(R\) 的所有元组所需块的数目,这个块的数目表示为 \(B( R)\) 。如果我们知道指的是关系 \(R\) ,就可以仅仅表示为 \(B\) 。通常,我们假设 \(R\) 是
聚集的,即 \(R\) 存储在 \(B\) 个块中或近似 \(B\) 个块中。 - 有时候,我们也需要知道 \(R\) 中的元组的数目,我们将这个数量表示为 \(T( R)\) 。或在我们知道所指关系为 \(R\) 时简记为 \(T\) 。如果我们需要一个块中能容纳的 \(R\) 的元组数,我们可以使用比例式 \(T/B\) 。
- 最后,我们有时候希望参考出现在关系的一个列中的不同值的数目。如果 \(R\) 是一个关系,它的一个属性是 \(a\) ,那么 \(V(R, a)\) 是 \(R\) 中 \(a\) 对应列上不同值的数目。更一般的,如果 \([a_{1}, a_{2}, a_{3}, …, a_{n}]\) 是一个属性列表,那么 \(V(R, [a_{1}, a_{2}, a_{3}, …, a_{n}])\) 是 \(R\) 中属性 \(a_{1}, a_{2}, a_{3}, …, a_{n}\) 对应列上不同的 \(n\) (元组的数目)。换而言之,它是 \(\delta(\pi_{a_{1}, a_{2}, a_{3}, …, a_{n}}( R))\) 。
2.5 扫描操作符的 \(I/O\) 代价
作为前面介绍的参数的一个简单应用,我们可以表示迄今为止讨论过的每个 表-扫描(index-scan) 操作符的磁盘 \(I/O\) 数目。如果关系 \(R\) 是聚集的,那么 表-扫描 操作符的磁盘 \(I/O\) 数目近似为 \(B\) 。同样,如果 \(R\) 能够全部装入主存,那么我们可以通过将 \(R\) 读入主存并做内排序,从而实现 排序-扫描(sort-scan) ,所需磁盘 \(I/O\) 仍是 \(B\) 。
但是,如果 \(R\) 不是聚集的,那么所需磁盘 \(I/O\) 数通常要高得多。如果 \(R\) 分布在其他关系的元组之间,那么 表-扫描 所需读的块数可能与 \(R\) 的元组一样多;即 \(I/O\) 代价为 \(T\) 。类似地,如果我们想把 \(R\) 排序,但是 \(R\) 能够被内存容纳,那么将 \(R\) 的全部元组调入内存所需磁盘 \(I/O\) 数 \(T\) 就是我们所需要的。
最后,让我们考虑 索引-扫描(index-scan) 的代价。通常关系 \(R\) 的一个索引需要的块数比 \(B( R)\) 少许多。因此,扫描整个 \(R\) (至少需要 \(B\) 次磁盘 \(I/O\) )比查看整个索引需要更多的 \(I/O\) 。这样,即便 索引-扫描 继续用检查关系又需要检查它的索引:
- 我们继续用 \(B\) 或 \(T\) 作为使用索引时访问整个聚集或不聚集的关系的代价估算。
但是,如果我们只想要 \(R\) 的一部分,我们通常能够避免查看整个索引和整个 \(R\)。我们将对索引的这个使用推迟到以后章节分析。
2.6 实现物理操作符的迭代器
许多物理操作符可以实现为 迭代器 。迭代器是三个方法的集合,这三个方法允许物理操作符结果的使用者一次一个元组地得到这个结果。这三个形成一个迭代器的方法是:
- Open()
- 这个方法启动获得元组的过程,但并不获得元组。它初始化执行操作所需的任何数据结构并为操作的任何对象调用 Open() 。
- GetNext()
- 这个方法返回结果中的下一个元组,并且对数据结构做必要的调整以得到后续元组。在获取下一个元组时,它通常在操作对象上
一次或多次地调用 GetNext() 。如果再也没有元祖返回了,GetNext()将返回特殊值 NotFound ,这个值肯定不会与任何元组混淆。 - Close()
- 这个方法在所有的元组或使用者想得到的所有元组均获得后终结迭代。它通常为操作符的每个操作对象调用 Close() 。
当描述迭代器和它们的函数时,我们假设每一类迭代器(例如,实现为迭代器的每一类物理操作符)都有一个“类“,这个”类“在它的实例上定义了 Open() 、 GetNext() 和 Close() 。
3. 一趟算法(One-Pass Algorithms)
我们在将开始学习查询优化中一个非常重要的问题:我们怎么执行逻辑计划中的每个单独的步骤(例如,连接或选择)?
每一个操作符的算法的选择是将逻辑查询计划转变为物理查询计划中必不可少的部分。关于各种操作符已提出了很多算法,它们大体上分为三类:
- 基于排序的算法
- 基于散列的算法
- 基于索引的算法
另外,我们将操作符算法按照难度和代价分为三种”等级”:
- 一些方法仅从磁盘读取一次数据,这就是 一趟(one-pass)算法 。它是这节的主题。它们通常要求操作的至少一个操作对象能完全装入内存,尽管存在例外尤其是选择(\(\sigma\))和投影(\(\pi\))。
- 一些方法处理的数量太大以至于不能装入可利用的内存,但又不是想象的最大的数据集合。这些 两趟(two-pass)算法 的特点是首先从磁盘读一遍数据,以某种方式处理,将全部或绝大部分写会磁盘,然后在第二趟为了进一步处理,在读一遍数据。
- 多趟算法: 某些方法对于处理的数据量没有限制。这些方法用三趟或更多趟来完成工作,它们是对两趟算法的自然的递归的推广。
我们将操作符分为三大类:
- 一次单个元组,一元操作
- 这类操作(选择和投影)不需要在一次在内存中装入整个关系,甚至也不需要关系的绝大部分。这样,我们可以一次读一个块,使用内存缓存池,并产生我们的输出。
- 整个关系,一元操作
- 这些单操作对象的操作需要一次从内存中看到所有或绝大部分元组,因此,一趟算法局限于大小约为\(M\)(内存中可用缓存区的数量)或更小的关系。这里我们考虑的属于这一类的操作是\(\gamma\)(分组操作符)和\(\delta\)(去重操作符)。
- 整个关系,二元操作
- 其他所有的操作可以归为这一类: 并、交、差、连接和积的集合形式以及包形式。除了包的并集,如果要使用一趟算法,那么这类操作中的每一个都要求至少一个操作对象的大小限制在 \(M\) 以内
3.1 一次单个元组操作的一趟算法
无论关系 \(R\) 能否被内存容纳,一次单个元组的运算 \(\sigma( R)\) 和 \(\pi( R)\) 都有显而易见的算法。
Figure 3: selection_projection_on_R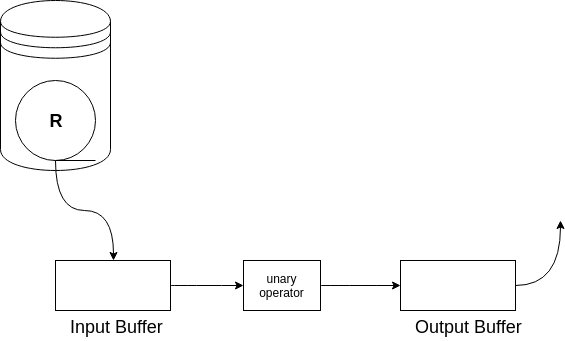
如上图所示,我们读取 \(R\) 的一块到输入缓冲区,对每一个元组进行操作,并将选出的元组或投影得到的元组移至输出缓冲区。由于输出缓冲区可能是其他操作的输入缓冲区,或正在向用户或应用发送数据,因此我们不把输出缓冲区算在所需空间内。因此,无论 \(B\) 有多大,我们只要求输入缓冲区满足 \(M \geq 1\) 。
这一过程的磁盘 \(I/O\) 需求取决于作为操作对象的关系 \(R\) 是怎么提供的。如果 \(R\) 最初在磁盘上,那么代价就是执行一个 表-扫描 或 索引-扫描 所需代价。通常,如果 \(R\) 是聚集的,代价就是 \(B\) ,如果 \(R\) 不是聚集的,代价就是 \(T\) 。然而有一个重要的例外是:当执行的操作是一个选择,且其条件是 比较 一个常量 和 一个带索引的属性 时,这种情况下,我们可以使用索引来检索 \(R\) 所在块的一个子集,这样通常会显著地提高执行效率。
额外的缓冲区可以加快操作
正如上图所示,尽管一次单个元组的操作只通过一个输入缓冲区和一个输出缓冲区就可以实现,但如果我们分配更多的缓冲区可以加速处理过程。
如果R存储在柱面上连续的块中,那么我们就可以读取完整是柱面到缓冲区,而仅为每一个柱面付出了一个块的查询时间和旋转延迟代价。类似地,如果操作的输出可以存储在全部的柱面上,我们在写上几乎不会浪费时间。3.2 整个关系的一元操作的一趟算法
现在让我们考虑施加于整个关系上而非施加于单个元组的一元操作: 消除重复 (\(\delta\))和 分组 (\(\gamma\))。
3.2.1 消除重复
为了消除重复,我们可以一次一个地读取 \(R\) 的每一块,但是对于每一个元组,我们需要判定:
- 这是我们第一次看到这个元组,这时将它复制到输出。
- 我们已经见过这个元组,这时不必输出它。
为支持这个判定,我们需要为见过的每一个元组在内存中保留一个备份。用一个内存缓冲区保存 \(R\) 的元组的一个块,其余的 \(M - 1\) 个缓冲区可以用来保存目前为止我们见过每一个元组的副本。
当存储已经见过的元组时,我们必须注意所使用的内存数据结构。我们可以简单地列出我们见过的所有元组。当考虑 \(R\) 中的一个新元组时,我们将它与迄今为止看到的所有元组比较,如果它与这些元组当中的任何一个都不相等,我们把它复制到输出并将它加入到存于内存中的我们所看到的元组列表中。
Figure 4: duplicate_elimination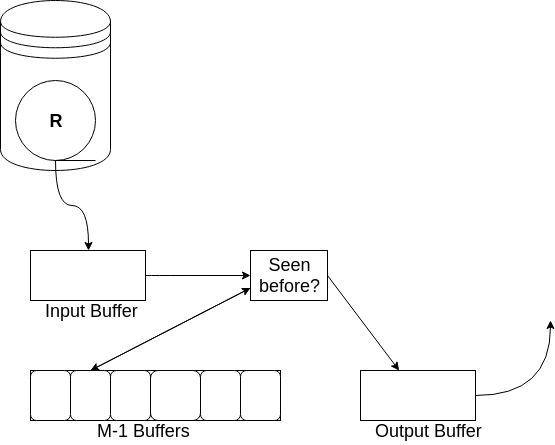
然而,如果内存中有 \(n\) 个元组,每一个新元组占用的处理器时间与 \(n\) 成比例。因此整个操作占用的处理器时间与 \(n^{2}\) 成比例。由于 \(n\) 可能非常大,对于我们所做的只有磁盘 \(I/O\) 需要大量时间这一假设来说,这样的时间量将带来严重的问题。因此,我们需要一个主存结构,它允许我们增加一个新元组并能够辨别一个给定的元组是否存在,它依赖于元组数量 \(n\) 增长。
例如,我们可以使用具有大量桶的散列表或某种形式的平衡二叉查找树。每一种结构除了需要存储元组的空间外,还需要一些开销。例如,一个主存散列表需要一个桶数组和连接桶内元组的指针空间。然而,所需额外空间开销与存储元组所需空间相比一般较小。因此在这里我们暂时忽略了这种开销。
基于这种假设,我们可以在主存的 \(M - 1\) 个可用缓冲区存储与 \(R\) 的 \(M - 1\) 个块所能容纳的一样多的元组。如果我们希望 \(R\) 的每个不同元组的一个副本能装在主存中,那么 \(B(\delta( R))\) 肯定不能超过 \(M - 1\) 。因此我们预计 \(M\) 远远大于 \(1\) ,我们将经常用到的这个规则的一个简单近似是:
\[B(\delta ( R) ) \leq M\]
注意,通常在计算出 \(\delta( R)\) 本身时,我们不能一般地计算出 \(\delta( R)\) 的大小。如果我们低估了这个大小,而 \(B(\delta( R))\) 实际上大于 \(M\) ,那么我们将为系统颠簸付出惨重的代价,因为保存 \(R\) 中不同元组的块必须频繁地出入主存。
3.2.2 分组
分组操作符 \(\gamma_{L}\) 给我们零个或多个分组属性以及可能的一个或多个聚集属性。如果我们在主存为每一个组(也就是为分组属性的每一个值)创建一个项,那么我们可以一次一次地扫描 \(R\) 的元组。每个组的 项(entry) 包括分组属性的值和每个聚集的一个或多个累计值。如下:
- 对 \(MIN(a)\) 或 \(MAX(a)\) 聚集来说,分别记录组内迄今为止见到的任意元组在属性 \(a\) 上的最小或最大值。每当见到组中的一个元组时,如果合适,就改变这个最小值或最大值。
- 对于任意 \(COUNT\) 聚集来说,为组中见到的每个元组加 \(1\) 。
- 对 \(SUM(a)\) 来说,如果 \(a\) 不为 NULL 的话,在它组里扫描到的累加值上增加属性 \(a\) 的值。
- \(AVG(a)\) 的情况比较复杂。我们必须保持两个累计值 组内元组个数 以及 这些元组在 \(a\) 上的值的和 。二者的计算分别与我们为 \(COUNT\) 和 \(SUM\) 聚集所做的一样。当 \(R\) 中所有元组都被扫描后,我们计算总和和个数的商得到平均值。
当 \(R\) 的全部元组都已经读到输入缓冲区中,并且已用于各自组中聚集的计算,我们就可以通过为每个组写一个元组来产生输出。注意,知道扫描最后一个元组后,我们才开始为 \(\gamma\) 操作创建输出。因此这种算法并不太适合迭代器结构;在 GetNext 能获得第一个元组之前, Open 方法必须将全部分组做好。
为了使每一个元组在内存的处理过程更有效,我们需要使用一个内存数据结构来帮助我们在已知分组属性值时找到各分组的项。就像前面讨论的 \(\delta\) 操作那样,通常的内存数据结构(如散列表或平衡二叉查找树)能发挥很好的作用。然而我们应该记住,这种结构的查找关键字只能是分组属性。
非聚簇数据上的操作
我们所有关于操作所需磁盘I/O数的计算都是在操作对象是聚簇的这一假设基础上进行的预测。在操作对象R没有聚簇的情况下(通常较罕见),
读取R的全部元组可能需要我们进行T(R)次而非B(R)次磁盘I/O。然而请注意,任何作为操作结果的关系总是可以被设想为聚簇的。因为我们没有理由以非聚簇的形式存储临时关系。这个一趟算法所需磁盘 \(I/O\) 数是 \(B\) ,与任何一元运算的一趟算法相同。尽管通常情况下 \(M\) 将小于 \(B\) ,但所需内存缓冲区 \(M\) 和 \(B\) 的关系不是任何一种简单的形式。问题在于组的项可能比 \(R\) 的元组长一些或短一些,并且组的数目可能是等于或小于 \(R\) 元组的数目的任意一种情况。然而大多数情况下,组的项不会比 \(R\) 的元组长,而且组的数目远小于元组数目。
3.3 二元操作的一趟算法
现在我们开始讨论二元操作: 并、交、差、积和连接。为了区分这些操作符对集合和包的版本,我们用 \(B\) 和 \(S\) 来分别表示包和集合,例如 \(\cup_{B}\) 是求包的集合,而 \(-_{S}\) 是求集合的差集。为了简化连接的讨论,我们仅考虑自然连接。将属性适当地重命名后,等值连接可以按照相同方式实现,并且 theta-连接 可以被认为是在 积 或 等值连接 后再跟上在等值连接中不能表达的条件。
包的并可以通过一种非常简单的一趟算法计算出来。为了计算 \(R \cup_{B} S\) ,我们复制元组 \(R\) 的每一个元组到输出,然后复制 \(S\) 的每一个元组。磁盘 \(I/O\) 数是 \(B( R) + B(S)\) ,正如操作对象 \(R\) 和 \(S\) 的一趟算法那样,并且不管 \(R\) 和 \(S\) 多么大, \(M=1\) 就够了。
其他的二元操作符需要将 \(R\) 和 \(S\) 中较小的那个操作数读到内存中并且建立一个合适的数据结构。要使元组不仅可以被快速插入还可以被快速检索到。散列表和平衡树即可满足要求。因此,在关系 \(R\) 和 \(S\) 上用一趟算法执行一个二元操作符的近似需求是:
\[min(B( R), B(S)) \leq M\]
更精确地讲,一个缓冲区将被用来读取较大关系的块,而大约 \(M\) 个缓冲区用来容纳整个较小的关系和它的内存结构。
现在我们将给出各个操作的细节。在每一种情况下,我们假设 \(R\) 是两个关系中较大的一个,并且我们把 \(S\) 放在内存中。
3.3.1 集合并(Set Union)
我们将 \(S\) 读到内存的 \(M-1\) 个缓冲区并且建立一个查找结构,其查找关键字是整个元组。所有的这些元组也都复制到输出。然后我们一次一块的将 \(R\) 的每一块读到第 \(M\) 个缓冲区。对于 \(R\) 的每一个元组 \(t\) ,我们观察 \(t\) 是否在 \(S\) 中,如果不在,我们就将 \(t\) 复制到输出。如果 \(t\) 也在 \(S\) 中,我们就跳过 \(t\) 。
Figure 5: set_union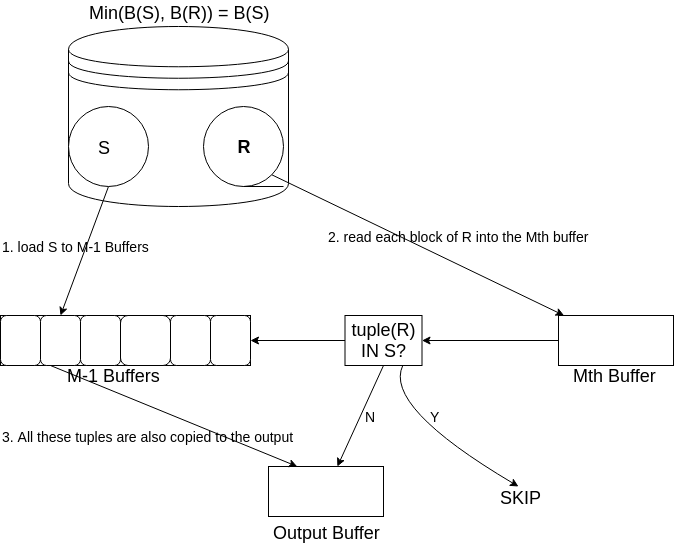
3.3.2 集合交(Set Intersection)
将 \(S\) 读到 \(M-1\) 个缓冲区并建立将整个元组作为查找关键字的查找结构。读取 \(R\) 的每一块,并且对 \(R\) 的元组 \(t\) ,观察 \(t\) 是否在 \(S\) 中。如果在,我们将 \(t\) 复制到输出,而如果不在,则忽略 \(t\) 。
Figure 6: set_union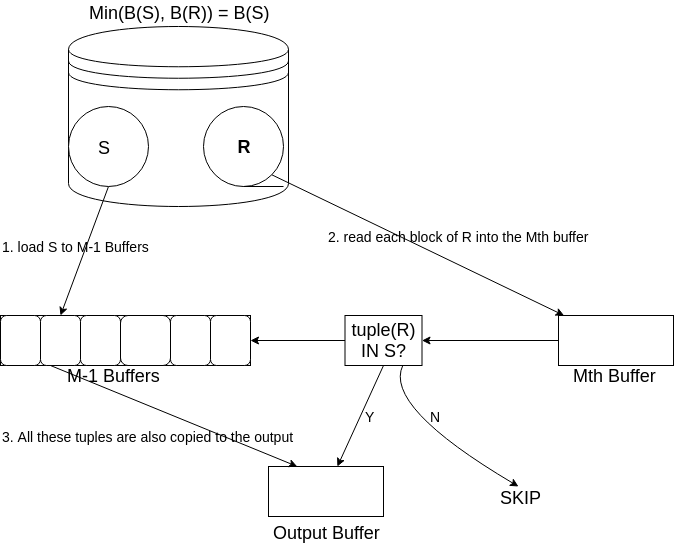
3.3.3 集合差(Set Difference)
既然差不是可交换的,我们必须区别 \(R-_{s}S\) 和 \(S-_{s}R\) ,并继续假设 \(R\) 是较大的关系。在两种情况下,我们都将 \(S\) 读到 \(M-1\) 个缓冲区中并建立将整个元组作为查找关键字的查找结构。
为了计算 \(R-_{s}S\) ,我们读取 \(R\) 的每一个块并检查块中的每一个元组 \(t\) 。如果 \(t\) 在 \(S\) 中,那么忽略 \(t\) ; 如果 \(t\) 不在 \(S\) 中,则将 \(t\) 复制到输出。
Figure 7: set_difference_r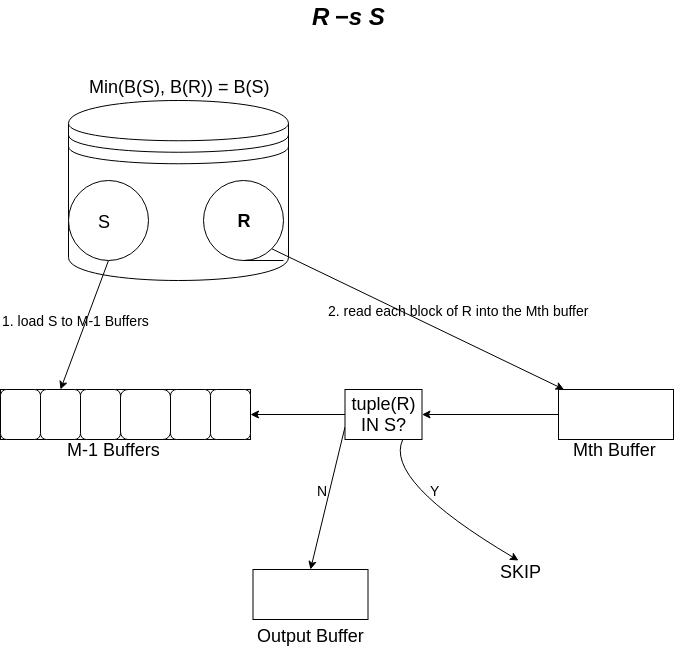
为了计算 \(S-_{s}R\) ,我们还是读取 \(R\) 的每一块,并一次检查每一个元组 \(t\) 。如果 \(t\) 在 \(S\) 中,那么我们从主存中 \(S\) 的副本删掉 \(t\) ,而如果 \(t\) 不在 \(S\) 中,则我们不做任何处理。在考虑完 \(R\) 的每一个元组后,我们将 \(S\) 中剩余的那些元组复制到输出缓冲区。
Figure 8: set_difference_s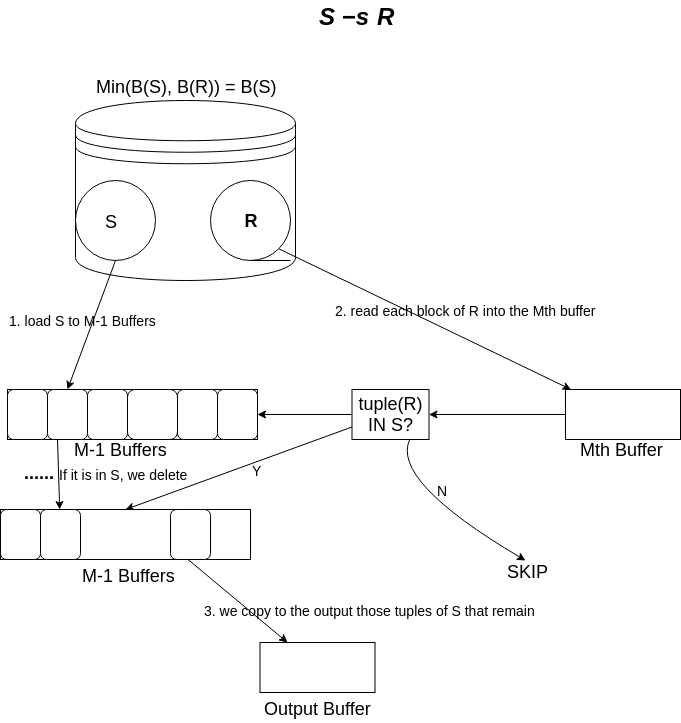
3.3.4 包交(Bag Intersection)
我们将 \(S\) 读到 \(M-1\) 个缓冲区中,但是我们把每一个不同的元组与一个 计数 联系起来,其初值是该元组在 \(S\) 中出现的次数。元组 \(t\) 的多个副本并不分别存储。相反地我们存储 \(t\) 的一个副本并且将它与一个计数联系起来,计数等于 \(t\) 出现的次数。
如果很少有重复的话,这种结构将占用比 \(B(S)\) 块稍大的空间,尽管结果经常是 \(S\) 被压缩。因此,我们将继续假设 \(B(S) \leq M - 1\) 足以运行一趟算法,尽管这个条件只是一个近似。
接着,我们读取 \(R\) 的每一块,并且对于 \(R\) 的每一个元组 \(t\) ,我们观察 \(t\) 是否在 \(S\) 中出现。如果不出现,那么我们忽略 \(t\) ; 它不会出现在交中。然而,如果 \(t\) 在 \(S\) 中出现,并且与 \(t\) 对应的计数仍为正值,那么我们输出 \(t\) 并将计数减 \(1\) 。如果 \(t\) 在 \(S\) 中出现,但是它的计数器已经到 \(0\) ,那么我们不输出 \(t\) ;
我们在输出中已经产生的 \(t\) 的副本与 \(S\) 中的一样多。
Figure 9: bag_intersection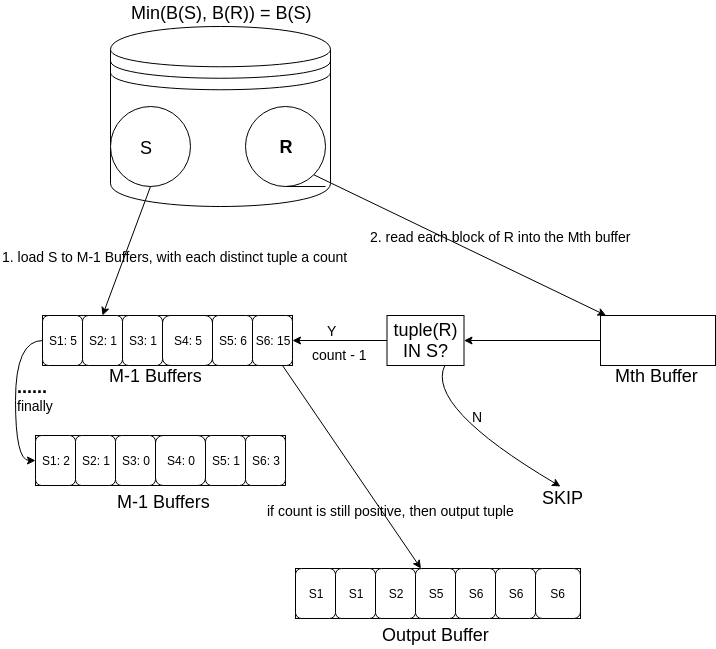
3.3.5 包差(Bag Difference)
为了计算 \(S -_{B} R\) ,我们将 \(S\) 的元组读到内存中,并且像我们在计算包交集的时那样统计每一个不同的元组出现的次数。当我们读取$R$时,对我们每一个元组 \(t\) ,我们观察 \(t\) 是否在 \(S\) 中出现,如果是,那么我们将与之对应的计数减 \(1\) 。最后,我们将内存中是计数是正数的每一个元组复制到输出,并且我们复制它的次数等于计数。
Figure 10: bag_difference_s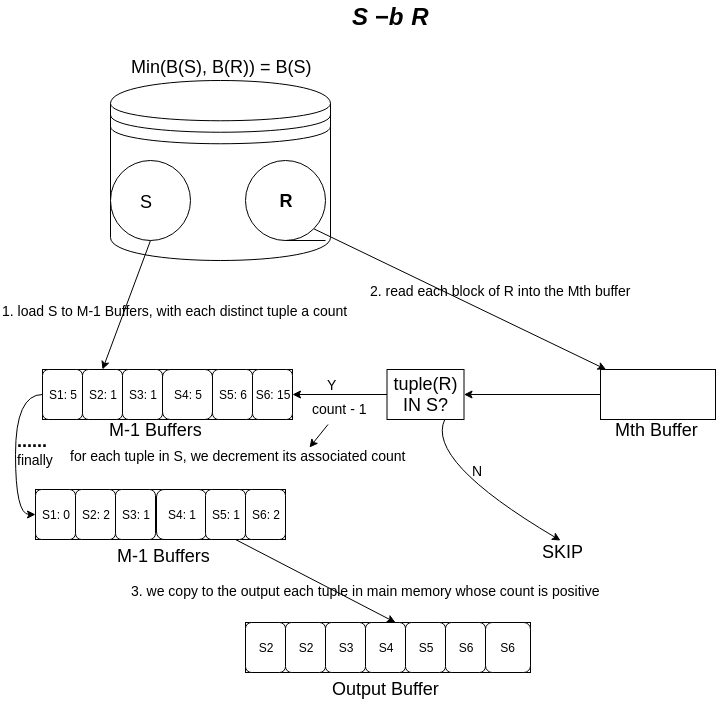
为了计算 \(R -_{B} S\) ,我们也将 \(S\) 的元组读到内存中,并且统计每一个不同的元组出现的次数。当我们读取 \(R\) 的元组时,我们可以把具有计数 c 的元组 \(t\) 看作是不将 \(t\) 复制到输出的 c 个理由。也就是说,当我们读取 \(R\) 的一个元组 \(t\) 时,我们观察 \(t\) 是否在 \(S\) 中出现。如果不出现,那么我们将 \(t\) 复制到输出。如果 \(t\) 确实在 \(S\) 中出现,那么我们与 \(t\) 对应的计数 c 的值。如果 \(c=0\) ,那么我们将 \(t\) 复制到输出。如果 \(c > 0\) ,那么不将 \(t\) 复制到输出,但将 c 的值减 \(1\) 。
Figure 11: bag_difference_r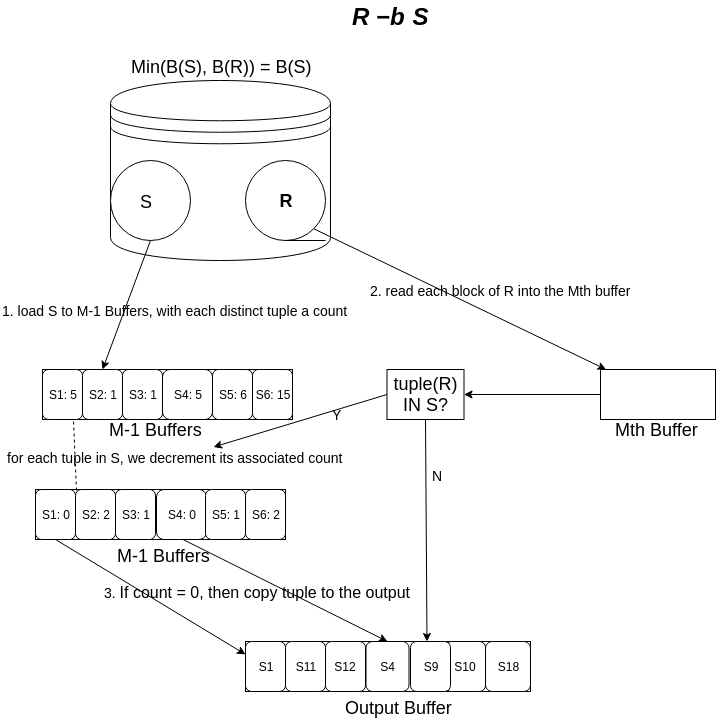
3.3.6 积(Product)
将 \(S\) 读到主存的 \(M-1\) 个缓冲区中,不需要特殊的数据结构。然后读取 \(R\) 的每一块,并且对 \(R\) 中的每一个元组 \(t\) ,将 \(t\) 与主存中 \(S\) 中的每一个元组连接。在每一个连接而成的元组一形成后立即将其输出。
对 \(R\) 的每一个元组,这种算法都可能占用相当多的处理器时间,因为每一个这样的元组必须和装满元组的 \(M-1\) 个块相匹配。然而,输出空间占用很大,而输出每个元组的时间很小。
3.3.7 自然连接(Natural Join)
在这一连接算法和其他连接算法中,我们沿袭惯例,即 \(R(X, Y)\) 与 \(S(Y, Z)\) 连接, \(Y\) 表示 \(R\) 和 \(S\) 的所有公共属性, \(X\) 是 \(R\) 的所有不在 \(S\) 中的属性,并且 \(Z\) 是 \(S\) 的所有的不在 \(R\) 中的属性。我们继续假设 \(S\) 是较小的关系。要计算自然连接,执行一下步骤:
- 读取 \(S\) 的所有元组,并且用它们构建一个以 \(Y\) 属性为查找关键字的内存查找结构。将内存的 \(M-1\) 块用于这里。
- 将 \(R\) 中的每一块读到内存中剩下的那一个缓冲区中。对于 \(R\) 的每一个元组 \(t\) ,利用查找结构找到 \(S\) 中与 \(t\) 在 \(Y\) 的所有属性上相符合的元组。对于 \(S\) 中的每一个匹配的元组,将它与 \(t\) 连接后形成一个元组,并且将结果移到输出。
和所有一趟的二元操作一样,这一算法读取操作对象需要使用 \(B( R) + B(S)\) 次磁盘 \(I/O\) 。只要 \(B(S) \leq M - 1\) 或近似地 \(B(S) \leq M\) ,他就能正常工作。
我们不打算讨论自然连接外的连接。记住,等值连接以和自然连接基本相同的方式执行,但是我们必须考虑两个关系的”相等”属性可能有不同的名字这一事实。不是等值连接的 theta-连接 可以用在等值连接或积之后加以选择来代替。
4. 嵌套循环连接
在讨论更为复杂的算法之前,我们需要将注意力转向一个称为 嵌套循环 连接的连接操作符算法系列。这些算法,在某种意义上来讲需要 一趟半(one-and-a-half-pass) ,因为在其中的各种算法中,两个操作对象有一个元组仅读取一次,而另一个操作对象将重复读取。嵌套循环连接可以用于任何大小关系;
它不是必须要求有一个关系能装入内存中。
4.1 基于元组的嵌套循环连接
嵌套循环系列中最简单的形式是其中的循环是对所涉及关系的各个元组来进行的。在这个我们称为 基于元组的嵌套循环连接 算法中,我们将计算连接 \(R(X, Y) \bowtie S(Y, Z)\) 如下:
FOR each tuple s IN S DO
FOR each tuple r IN R DO
IF r and s join to make a tuple t THEN
output t;如果我们不注意关系 \(R\) 和 \(S\) 的块的缓冲方法,那么这种算法需要的磁盘 \(I/O\) 可能多达 \(T( R)T(S)\) 。然而,在很多情况下这种算法都可以修改,使代价低得多。
- 一种情况是当我们可以使用 \(R\) 连接属性上的索引来查找与给定的 \(S\) 元组匹配的 \(R\) 元组时,这样的匹配不必读取整个关系 \(R\) 。
- 第二种改进更加注重 \(R\) 和 \(S\) 的元组在各个块中的分布方式,并且在我们执行内层循环时,要尽可能多地使用内层,以减少磁盘 \(I/O\) 的数目。
4.2 基于元组的嵌套循环连接的迭代器
嵌套循环连接的一个优点是它非常适用于迭代器结构,因此,在某种情况下它能使我们避免将中间关系存储在磁盘上。 \(R \bowtie S\) 的迭代器很容易用 \(R\) 和 \(S\) 的迭代器构造起来,我们用 R.Open() 等表示这个迭代器。嵌套循环连接的3个迭代函数的代码如下所示,它假定关系 \(R\) 和 \(S\) 都是非空的。
Open() {
R.Open();
S.Open();
s := S.GetNext();
}
GetNext() {
REPEAT {
r := R.GetNext();
IF (r == NotFound) { /* R is exhausted for the current s */
R.Close();
s := S.GetNext();
IF (s == NotFound) {
RETURN NotFound; /* both R and S are exhausted */
}
R.Open();
r := R.GetNext();
}
}
UNTIL (r and s jon);
RETURN the join of r and s;
}
Close {
R.Close();
S.Close();
}4.3 基于块的嵌套循环连接算法
如果我们按以下步骤计算 \(R \bowtie S\) ,我们可以改进上面提到的基于元组的嵌套循环连接:
- 对作为操作对象的两个关系的访问均按块组织。
- 使用尽可能多的内存来存储属于关系 \(S\) 的元组, \(S\) 是外层循环中的关系。
第1点确保了当在内层循环中处理关系 \(R\) 的元组时,我们可以用尽可能少的磁盘 \(I/O\) 来读取 \(R\) 。第2点使我们不是将读到的 \(R\) 的每一个元组与 \(S\) 的一个元组连接,而是与能装入内存的尽可能多的 \(S\) 元组连接。
让我们继续假设 \(B(S) \leq B( R) \& B(S) > M\) ,也就是说任何一个关系都不能完整地装入内存。我们重复地将 \(M - 1\) 个块读到内存缓冲区中。为 \(S\) 在内存的元组创建一个查找结构,它的查找关键字是 \(R\) 和 \(S\) 的公有属性。然后我们浏览 \(R\) 的所有块,依次读取每一块到内存的最后一块。我们在读入 \(R\) 的一个块后将块中所有元组与 \(S\) 在内存中所有块的所有元组进行比较。对于那些能连接的元组,我们输出连接得到元组。
FOR each chunk of M-1 blocks of S DO BEGIN
read these blocks into main-memory buffers;
organize their tuples into a search structure whose search key is the common attributes of R and S;
FOR each block b of R DO BEGIN
read b into main-memory;
FOR each tuple t of b DO BEGIN
find the tuples of S in main-memory that join with t;
output the join of t with each of these tuples;
END;
END;
END;上述算法有时被称作 嵌套块连接 。我们将继续将其简单地称为 嵌套循环连接 ,因为它是嵌套循环思想在实践中使用最广泛的实现形式。
上述程序似乎有三重嵌套循环。然而,如果我们从正确的抽象层次上看代码,实际上仅有两重循环。第一重循环或外层循环是对 \(S\) 元组进行的,其他的两层循环是对 \(R\) 的元组进行。然而我们将此过程表达为两层循环是为了强调我们访问 \(R\) 的元组的顺序不是任意的。相反的,我们需要一次一块地处理这些元组(第二层循环的作用),并且在继续移动到下一块之前,我们要处理当前块内的所有元组(第三层循环)。
样例
假定 \(B( R) = 1000\) 且 \(B(S) = 500\) ,并令 \(M = 101\) 。我们将使用 \(100\) 个内存块来按照大小为 \(100\) 块的 chunk 对 \(S\) 进行缓冲,因此 嵌套循环连接 的外层循环需迭代 \(5\) 次。每一次迭代中。我们用 \(100\) 个磁盘 \(I/O\) 读取 \(S\) 的 chunk ,并且在第二层循环中我们必须使用 \(1000\) 个磁盘 \(I/O\) 来完整地读取 \(R\) 。因此,磁盘 \(I/O\) 的总的数量是 \(5500\) 。
注意,如果我们颠倒 \(R\) 和 \(S\) 的角色,算法使用的磁盘 \(I/O\) 要略多一些。我们将在外层循环中迭代 \(10\) 次,并且每一次迭代使用 \(500 + 1000 \div 10 = 600\) 次磁盘 \(I/O\) ,总共是 \(6000\) 次。一般来说,在外层循环中使用较小关系略有优势。
4.4 嵌套循环连接的分析
4.3中的样例可以重复应用在任何 \(B( R)\) 、 \(B(S)\) 和 \(M\) 上。假设 \(S\) 是较小的关系, chunk 数或外层循环的迭代次数是 \(B(S) / (M - 1)\) 。每一次迭代时,我们读取 $S$的\(M - 1\) 个块和 \(R\) 的 \(B( R)\) 个块。这样磁盘 \(I/O\) 数量是 \(B(S)(M - 1 + B( R)) / (M - 1)\) 或者 \(B(S) + (B(S)B( R)) / (M - 1)\) 。
设想 \(M\) 、 \(B(S)\) 和 \(B( R)\) 都很大,但 \(M\) 是其中最小的,上面的公式的一个近似值是 \(B(S)B( R) / M\) 。也就是说,代价与两个关系大小的乘积再除以可用内存容量得到的商成比例。当两个关系都很大时我们可以做得比嵌套循环连接好得多。尽管我们应当注意对于像4.3中那样相当小的实例来说,嵌套循环连接的代价并不比一趟连接的代价(对于该例子来说是1500次磁盘 \(I/O\) )大多少。实际上,如果 \(B(S) \leq M - 1\) ,嵌套循环连接与一趟连接算法是一样的。
经管嵌套循环连接通常并不是可能的连接算法中最有效的算法,我们应该注意在一些早期的关系 DBMS 中,它是唯一可用的方法。即使今天,某些情况下在更有效的连接算法中,仍然需要把它作为一个子程序,例如,当各个关系中大量元组在连接属性上具有相同的值时。
4.5 迄今为止的算法的总计
下面的表格给出了第3和第4节中我们已经讨论过的算法的内存和磁盘 \(I/O\) 需求。 \(\gamma\) 和 \(\delta\) 的内存需求实际上比给出的更复杂,并且 \(M = B\) 仅是一个大概的近似。对于 \(\gamma\) , \(M\) 随组的数量增长,而对于 \(\delta\) , \(M\) 随不同元组的数量增长。
| Operators | Approximate M required | Disk I/O |
|---|---|---|
| \(\sigma\) , \(\pi\) | \(1\) | \(B\) |
| \(\gamma\) , \(\delta\) | \(B\) | \(B\) |
| \(\cup\) , \(\cap\) , \(-\) , \(\times\) , \(\bowtie\) | \(min(B( R), B(S))\) | \(B( R) + B(S)\) |
| \(\bowtie\) | \(any M \geq 2\) | \(B(S) + (B(S)B( R))/(M - 1) \approx B( R)B(S)/M\) |
5 基于排序的两趟算法
现在,我们开始学习关系上执行关系代数操作的多趟算法,这里的关系大于之前我们所讲的一趟算法所能够处理的关系。我们的重点在两趟算法上,其中来自于操作对象关系中的数据被读到内存,以某种方式处理,在写回磁盘,然后在重新读取磁盘以完成操作。我们可以自然地将这种想法扩展到任何趟数,其中数据被多次读取到内存。然而,我们将重点放在两趟算法上,这是因为:
a). 即使对于很大关系,两遍通常也就够了。
b). 将两趟算法推广到多趟并不难。
我们可以用排序操作符 \(T\) 的实现来阐述普通方法:对于 \(B( R) > M\) 的关系 \(R\) ,将它分为大小为 \(M\) 的 chunk 并排序,然后以某种对于任意子表在任意时刻只占用一个内存块的方式,对排序好的子表进行排序。
5.1 两阶段多路归并排序
假设我们有 \(M\) 个内存缓冲区来进行排序,可以通过两趟的算法对非常大的关系进行排序,这种方法叫 两阶段多路归并排序(Two-Phase, Multiway Merge-Sort, TPMMS) 。 TPMMS 用如下的方法对关系 \(R\) 进行排序:
- 阶段1
- 不断将 \(R\) 中的元组放入 \(M\) 个缓冲区,利用主存排序算法对它们进行排序,并将排序得到的子表存到外存中。
- 阶段2
- 找到所有子表中的第一个元素的最小值。因为比较是在内存中完成的,因此线性的搜索就足够了,搜索执行的机器指令的数量与子表的数量成正比。但是如果我们需要的话,可以利用基于 优先队列 的方法,使找到子表第一个元素的最小时间与子表数量的对比成正比。
- 将最小的元素移至输出块的第一个可用的位置。
- 如果输出块已满,则将它写入硬盘,并对内存中该缓冲块进行重新初始化,以便存放下一个输出块。
- 如果刚被取出最小元素的缓冲块的元素已耗尽,将同一个有序子表的下一个块读入到元素耗尽的缓冲块。如果子表中没有块了,则使它的缓冲区保持空,并在以后选择最小的列表的第一个元素的操作中不对它进行考虑。
- 找到所有子表中的第一个元素的最小值。因为比较是在内存中完成的,因此线性的搜索就足够了,搜索执行的机器指令的数量与子表的数量成正比。但是如果我们需要的话,可以利用基于 优先队列 的方法,使找到子表第一个元素的最小时间与子表数量的对比成正比。
Figure 12: main-memory organization for multiway merging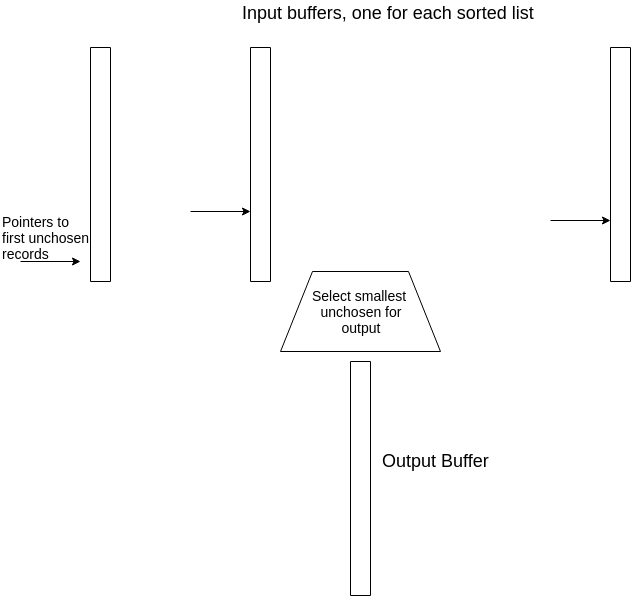
为了使 TPMMS 能正常工作,子表不能超过 \(M-1\) 个。假设 \(R\) 占用 \(B\) 个块。因为每个子表包含 \(M\) 个块,于是子表的数目为 \(B/M\) 。因此我们要求 \(B/M \leq M -1\) ,或者 \(B \leq M (M - 1)\) (或者近似表达为 \(B \leq M^{2}\) )。
算法要求我们在第一趟时读入 \(B\) 个块,此外还有 \(B\) 次磁盘 \(I/O\) 用于写回排好序的子表。每个子表在第二阶段都会被读入内存,因此总的磁盘 \(I/O\) 次数为 \(3B\) 。如果按照惯例,我们不计算将结果写回到磁盘的代价(因为此结果可能是用于流水线操作而不用写回到磁盘),那么 \(3B\) 就是排序操作符 \(\tau\) 所需的总的代价。但是,如果我们需要将结果保存到磁盘,那么总的代价就是 \(4B\) 。
样例
假设块的大小是 \(64k\) 字节,而我们有 \(1G\) 的内存。那么我们可以提供的 \(M\) 为 \(16k\) 。于是,要能对一个有 \(B\) 个块的关系进行排序,则要求 \(B\) 的大小不超过 \((16k)^{2} = 2^{28}\) 。因为块的大小是 \(64k=2^{14}\) ,那么大小不超过 \(2^{42}\) 字节或 \(4T\) 字节的关系都能进行排序。
这个例子告诉我们即使是使用普通的机器, 2PPMS 可以利用两趟对相当大的关系进行排序。但是,如果你有更大的关系,相同的思想可以递归式地使用。将关系分为 \(M(M-1)\) 个片段,使用 2PPMS 对其中的每一个片段进行排序,并将排序结果作为第三趟需要用到的子表。这个思想可以被扩展到更多的趟数。
5.2 利用排序去除重复
为了用两趟 \(\delta( R)\) 操作,我们像在 2PPMS 中一样在子表中将 \(R\) 的元组排序。在第二趟中,我们将采取与 2PPMS 相同的方法,在可用内存中为每个有序子表分配一个缓冲块,并保持一个输出缓冲块。但是,我们将在第二趟时不断重复地复制每一块的第一个未考虑的元组 \(t\) 到输出缓冲块中并忽略与它相同的所有元组,而不是进行排序。我们将 \(t\) 拷贝到输出块,并将输出块中所有的 \(t\) 删除。因此,输出块对 \(R\) 中的任何一个元组都只有一个实例;而它们是按序产生的。如果缓冲块已满或这输入块已空,我们用 2PPMS 中相同的方法进行处理。
和平常一样忽略对输出的处理,执行这个算法的磁盘 \(I/O\) 数和排序一样,也是 \(3B( R)\) 。这个数字可以与之前的一趟算法的 \(B( R)\) 进行比较。另一方面,我们可以用两趟算法处理比一趟算法所能处理的文件大得多的文件。对 2PPMS 来说,与一趟算法 \(B \leq M\) 相比,要使两趟算法可行,需要使 \(B \leq M^{2}\) 。换而言之,用两趟算法计算 \(\delta( R)\) 仅需要 \(\sqrt{B( R)}\) 个内存块,而不是 \(B( R)\) 个内存块。
5.3 利用排序进行分组和聚集
\(\gamma_{L}( R)\) 的两趟算法与 \(\delta( R)\) 或是 2PPMS 的算法非常相似。我们将它概括如下:
- 将 \(R\) 的元组每次读取 \(M\) 块到内存中。用 \(L\) 的分组属性作为排序关键字,对每 \(M\) 块排序。将每一个排好序的子表写入磁盘中。
- 为每一个子表使用一个主存缓冲区,并且首先将每一个子表的第一个块装入其缓冲区。
- 在缓冲区可以获得的第一个元组中反复查找排序关键字(分组属性)的最小值。这个最小值 \(v\) 称为下一分组,我们为它:
- 准备在这个分组的列表 \(L\) 上计算所有的聚集。就像在一趟算法中那样,使用计数和求和来代替求平均。
- 检查每个排序关键字为 \(v\) 的元组,并且累计所需聚集。
- 如果一个块的缓冲区空了,则用同一子表中的下一块替换它。
- 准备在这个分组的列表 \(L\) 上计算所有的聚集。就像在一趟算法中那样,使用计数和求和来代替求平均。
当不再有排序关键字为 \(v\) 的元组时,输出一个由 \(L\) 的分组属性和对应的我们已经为这个组计算出的聚集值构成的元组。
正如 \(\delta\) 算法那样, \(\gamma\) 的这种两趟算法使用 \(3B( R)\) 次磁盘 \(I/O\) ,而且只要 \(B( R) \leq M^{2}\) 就可以正常工作。
5.4 基于排序的并算法
当需要包的并时,简单地复制两个关系的一趟算法就可以。这一算法的正常工作与操作对象的大小无关,因而我们不用考虑 \(\cup_{B}\) 的两趟算法。然而,只有当至少一个关系小于可用的主存时, \(\cup_{S}\) 的一趟算法才起作用,因此,我们应该考虑集合并操作的两趟算法。正如我们在下一章节将要看到的那样,我们提出的方法对于集合和包的交和差也都适合。
- 在第一趟的时候,创建关系 \(R\) 和 \(S\) 的子表。
- 为 \(R\) 和 \(S\) 的每一个子表使用一个内存缓冲区,用对应子表的第一块初始化各缓冲区。
- 重复地在所有缓冲区中查找第一个剩余的元组 \(t\) 。将 \(t\) 复制到输出,并且从缓冲区中删除 \(t\) 的所有副本(如果 \(R\) 和 \(S\) 都是集合则至多有两个副本)。当输入缓冲区为空或者输出缓冲区变满时,采用和 2PPMS 相同的方法进行处理。
我们看到, \(R\) 和 \(S\) 的每一个元组被两次读进内存,一次是当子表创建的时,第二次是作为子表的一部分。元组还写回磁盘一次,作为新建子表的一部分。因此,磁盘的 \(I/O\) 的代价是 \(3(B( R) + B(S))\) 。
因为我们对每一个子表需要一个缓冲区,输出也需要一个缓冲区,所以只要两个关系的子表数不超过 \(M-1\) 。这样,近似的,两个关系的大小之和不能超过 \(M^{2}\) ;即 \(B( R) + B(S) \leq M^{2}\) 。
5.5 基于排序的交和差算法
无论是要计算集合形式还是包形式,算法基本上与上节所用的相同,除了我们在处理已排序子表前面的元组 \(t\) 的副本的方式不同。对每一种算法,我们不断考虑所有缓冲区内剩余的元组中的最小元组 \(t\) 。我们用如下方式产生结果,并将输入缓冲区里所有 \(t\) 的拷贝移除。
- 对于集合交,如果 \(t\) 在 \(R\) 和 \(S\) 中都出现就输出 \(t\) 。
- 对于包交,输出 \(t\) 的次数是它在 \(R\) 和 \(S\) 中出现的最小次数。注意,如果两个技术中有一个为0,就不输出 \(t\) ;也就是说,当 \(t\) 在一个或两个关系中未出现时就不输出它。
- 对于集合差, \(R -_{S} S\) ,当且仅当 \(t\) 出现在 \(R\) 中但不在 \(S\) 中输出 \(t\) 。
- 对于包差, \(R -_{B} S\) ,输出 \(t\) 的次数是 \(t\) 在 \(R\) 中出现的次数减去在 \(S\) 中出现的次数。当然,如果 \(t\) 在 \(S\) 中的次数至少等于在 \(R\) 中出现的次数,那就不要输出 \(t\) 。
对于包的操作,有个微妙的地方需要注意。当计算 \(t\) 的出现次数时,可能一个输入缓冲块的所有剩余元组都是 \(t\) 。如果是这样,在子表的下一块中可能还有更多的 \(t\) 。因此,当一个块中仅有 \(t\) 剩余时,我们必须读入子表的下一块继续计算 \(t\) 的次数。这个过程可能需要在若干块中继续,还可能需要对若干个子表进行。
这一类算法分析和上节对集合并算法所做分析相同:
- \(3(B( R) + B(S))\) 次磁盘 \(I/O\) 。
- 为使算法能工作,近似地要求 \(B( R) + B(S) \leq M^{2}\) 。
5.6 基于排序的一个简单的连接算法
将排序用于连接大的关系的方法有多种。在讨论连接算法之前,我们来看一个在计算连接时可能出现的问题,但这个问题不是迄今为止考虑过的二元操作的问题。在计算连接时,两个关系中在连接属性上具有相同的值,因而需要同时放入内存中的元组,但这可能会超过内存所能容纳的数量。极端的例子是当连接属性仅有一个值时,这是一个关系中的每个元组与另一个关系的每个元组都能连接。这种情况下,除了对在连接属性上值相等的两个元组集合进行嵌套循环连接外,就真的没有其他选择了。
为了避免这种情形,我们可以尽量减少为算法中其他方面所使用的内存,因而可以用大量缓冲区保存给定连接属性值的元组。这一节我们讨论一个算法,它可以为具有共同的值的元组连接获取最大量的可用缓冲区。在以后章节中,我们考虑另一个使用较少的磁盘 \(I/O\) 的并且基于排序的算法,但该算法在大量的元组在连接属性上具有共同的值时可能会出现问题。
已知将要连接的关系 \(R(X, Y)\) 和 \(S(Y, Z)\) ,并且已知有 \(M\) 块内存用作缓冲区,我们做下面的事情:
- 用 \(Y\) 作为排序关键字,使用 2PPMS 对 \(R\) 进行排序。
- 类似地对 \(S\) 进行排序。
- 归并排好序的 \(R\) 和 \(S\) 。我们仅用两个缓冲区,一个给 \(R\) 的当前块,另一个给 \(S\) 的当前块。重复以下步骤:
- 在当前 \(R\) 和 \(S\) 的块的前面查找连接属性 \(Y\) 的最小值 \(y\) 。
- 如果 \(y\) 在另一个关系的前面没有出现,那么删除具有排序关键字 \(y\) 的元组。
- 否则,找出两个关系中具有排序关键字 \(y\) 的所有元组。如果需要,从排序的 \(R\) 和(或) \(S\) 中读取块,直到我们确定每一个关系中都不再有 \(y\) 的副本。最多可以用 \(M\) 个缓冲区来做这件事情。
- 输出通过连接 \(R\) 和 \(S\) 中具有共同的 \(Y_{y}\) 值的元组所能形成的所有元组。
- 如果一个关系在内存中已没有未考虑的元组,就重新加载为那个关系所设的缓冲区。
- 在当前 \(R\) 和 \(S\) 的块的前面查找连接属性 \(Y\) 的最小值 \(y\) 。
样例
让我们考虑关系 \(R\) 和 \(S\) ,这两个关系分别占用 \(1000\) 和 \(500\) 个块,并且有 \(M = 101\) 个缓冲区。当我们在一个关系上使用 2PPMS 时,对每一个块我们使用 \(4\) 次磁盘 \(I/O\) ,而每个阶段有两次。那么,对 \(R\) 和 \(S\) 排序我们要使用 \(4(B( R) + B(S))\) 次磁盘 \(I/O\) ,或 \(6000\) 次磁盘 \(I/O\) 。
当我们归并 \(R\) 和 \(S\) 以得到连接的元组时,我们用另外的 \(1500\) 次磁盘 \(I/O\) 来第五次读取 \(R\) 和 \(S\) 的每一个块。这个归并中,我们通常仅需要 \(101\) 个内存块中的两个。然而,如果需要,我们可以使用所有 \(101\) 个块来容纳具有公共值 \(Y_{y}\) 的 \(R\) 和 \(S\) 的元组。因此,只要对于任意的 \(y\) , \(R\) 和 \(S\) 中的 \(Y\) 值为 \(y\) 的元组占用的空间不超过 \(101\) 块,这就足够了。
注意,这个算法执行的磁盘 \(I/O\) 总数量是 \(7500\) ,而之前 嵌套循环连接 的是 \(5500\) 。然而,嵌套循环连接是一个天生的二次方的算法,占用的时间与 \(B( R)B(S)\) 成正比例,而排序连接具有线性的 \(I/O\) 代价,占用的时间与 \(B( R) + B(S)\) 成比例。仅仅是因为常数因子以及较小的实例关系(每一个关系只不过比一个能完全装入分配的缓冲区中的关系大 \(5\) 或 \(10\) 倍),嵌套块连接才更可取。
5.7 简单的排序连接的分析
对于操作对象的每个块,排序连接执行了 \(5\) 次磁盘 \(I/O\) 。我们还需要考虑为了使简单的排序连接能够运行, \(M\) 需要多大。主要的限制在于我们必须能够在 \(R\) 和 \(S\) 上执行两阶段多路归并排序。就如我们之前所讲,执行这些排序,我们需要 \(B( R) \leq M^{2}\) 和 \(B(S) \leq M^{2}\) 。另外,我们要求具有一个公共的 \(Y_{y}\) 值的所有元组必须全部装入 \(M\) 个缓冲区。总之:
- 简单排序连接使用 \(5B(B( R) + B(S))\) 次磁盘 \(I/O\) 。
- 为了能工作,它要求 \(B( R) \leq M^{2} \&\& B(S) \leq M^{2}\) 。
- 它也要求用于连接的属性具有公共的值的所有元组必须能全部装入 \(M\) 个缓冲区。
5.8 一种更有效的基于排序的连接
如果我们不用担心在连接属性上具有公共值的元组太多,那么我们可以讲排序的第二阶段和连接本身合并,这样对每个块而言可以节约两次磁盘 \(I/O\) 。我们称这个算法为 排序-连接 ;还有一些其他的名字如 归并-连接 和 * 排序-归并-连接* 也指这个算法。为了用 \(M\) 个缓冲区计算 \(R(X, Y) \bowtie S(Y, Z)\) ,我们:
- 用 \(Y\) 做排序关键字,为 \(R\) 和 \(S\) 创建大小为 \(M\) 的排序的子表。
- 将每一个子表的第一块调入缓冲区;我们假设总共不超过 \(M\) 个子表。
- 重复地在所有子表的第一个可以得到的元组中查找最小的 \(Y_{y}\) 值。识别两个关系中具有 \(Y_{y}\) 值的所有元组,如果子表数少于 \(M\) ,可能使用 \(M\) 个缓冲区中的一部分来容纳这些元组。输出 \(R\) 和 \(S\) 中具有此公共 \(Y_{y}\) 值的所有元组的连接。如果一个子表的缓冲区处理完毕,则重新将磁盘上的块装入其中。
样例
使用 \(101\) 个缓冲区连接关系 \(R\) 和 \(S\) ,它们分别有 \(100\) 块和 \(500\) 块。我们将 \(R\) 分为 \(10\) 个子表,将 \(S\) 分为 \(5\) 个子表,每一个子表的长度为 \(100\) ,并且对它们排序。然后我们用 \(15\) 个缓冲区来容纳各子表的当前块。如果我们面临着许多元组都有某个固定的 \(Y_{y}\) 值的情况,我们可以用剩下的 \(86\) 个缓冲区来存储这些元组。
我们为数据的每个块执行三次磁盘 \(I/O\) 。其中两次是为了创建排序的子表。然后,在多路归并过程中,每一个排序子表的每一块被再次读取到内存中。因此,总的磁盘 \(I/O\) 数是 \(4500\) 。
这个排序算法在能够使用时比 简单排序连接 算法更有效。正如样例所讲,磁盘 \(I/O\) 的数目是 \(3(B( R) + B(S))\) 。我们可以在和前面的算法中几乎一样多的数据上执行这个算法。排序子表的长度是 \(M\) 块,而且两个关系总的子表数至多是 \(M\) 。因此, \(B( R) + B(S) \leq M^{2}\) 就足够了。
5.9 基于排序的算法的总结
下面的表格是对 \(5\) 节中我们讨论过的算法的分析。连接算法对在连接属性上具有相同的值的元组个数有限制。如果超出了限制,我们将采用嵌套循环连接。
| Operators | Approximate \(M\) required | Disk \(I/O\) |
|---|---|---|
| \(\tau\),\(\gamma\),\(\delta\) | \(\sqrt{B}\) | \(3B\) |
| \(\cup\),\(\cap\),\(-\) | \(\sqrt{B( R)+B(S)}\) | \(3(B( R)+B(S))\) |
| \(\bowtie\) (simple sort-based join) | \(\sqrt{max(B( R),B(S))}\) | \(5(B( R)+B(S))\) |
| \(\bowtie\) (sort-merge-join) | \(\sqrt{B( R)+B(S)}\) | \(3(B( R)+B(S))\) |
6. 基于散列的两趟算法
如果有数据量太大以至于不能存入内存缓冲区中,就使用一个合适的散列关键字散列一个或多个操作对象的所有元组。对于所有通常的操作,都有一种选择散列关键字的方法,它能使在我们执行该操作时需要一起考虑的所有元组分配到相同的桶。
然后,我们通过一次处理一个桶(或者在二元操作运算的情况下,通过一次处理具有相同散列值的一对桶)的方式执行操作。实际上,我们已经减少了操作对象的大小,减小的比例等于桶的数目,它的数量大致为 \(M\) 。注意的是,第 \(5\) 节中基于排序的算法通过预处理也获得了一个因子 \(M\) ,尽管排序和散列这两种方法达到这一相似的成果的办法各不相同。
6.1 通过散列划分关系
首先我们回顾接受关系 \(R\) 并使用 \(M\) 个缓冲区将 \(R\) 划分为大小大致相等的 \(M-1\) 个桶的方式。我们假设 \(h\) 是散列函数,并且将 \(R\) 的整个元组作为参数(也就是说, \(R\) 的所有属性都是散列关键字的一部分)。我们将一个桶和一个缓冲区关联起来。最后一个缓冲区用来每次一块地装入 \(R\) 的块。块中的每个元组 \(t\) 被散列到桶 \(h(t)\) 并且复制到适当的缓冲区中。如果缓冲区满了,我们就将它写入磁盘并且为同一个桶初始化另一个块。最后,对于每个桶的最后一块,如果它不空的话,我们将它写入磁盘。
initialize M-1 buckets using M-1 empty buffers;
FOR each block b of realation R DO BEGIN
read block b into the Mth buffers;
FOR each tuple t in b DO BEGIN
IF the buffer for bucket h(t) has no room for t THEN
BEGIN
copy the buffer to disk;
initialize a new empty block in that buffer;
END;
copy t to the buffer for bucket h(t);
END;
END;
FOR each bucket DO
IF the buffer for this bucket is not empty THEN
write the buffer to disk;6.2 基于散列的消除重复算法
现在,对于各种可能需要两趟算法的关系代数操作,我们来考虑基于散列的算法的细节。首先考虑消除重复的消除,即操作 \(\delta( R)\) 。按照S.6.1所讲,我们将 \(R\) 散列到 \(M-1\) 个桶。注意,相同元组 \(t\) 的两个副本将散列到同一个桶中。因此,我们可以一次检查一个桶,在该桶中独立地执行 \(\delta\) ,并且把 \(\delta(R_{i})\) 的并作为结果,其中 \(R_{i}\) 是 \(R\) 中散列到第 \(i\) 个桶的那一部分。之前所讲的 一趟算法 可以用来依次去除每个 \(R_{i}\) 中的重复,并将产生的唯一元组写回磁盘。
只要每一个 \(R_{i}\) 小道能装入内存因而允许使用一趟算法,这个方法就可行。因为我们假设散列函数 \(h\) 将 \(R\) 划分到大小相同的桶中,那么每一个 \(R_{i}\) 的近似大小为 \(B( R)/M-1\) 个块。如果这一块数小于等于 \(M\) ,即 \(B( R)\leq M(M-1)\) ,那么基于散列的两趟算法就可行。事实上,就像我们在 一趟算法 章节所讲一样,只要每个桶中不同元组的数量能被 \(M\) 个缓冲区容纳就可以。所以,一个保守估计是 \(B( R) \leq M^{2}\) ( \(M\) 和 \(M-1\) 本质上相同),和基于排序去重的两趟算法一样。
磁盘 \(I/O\) 的数量也于基于排序的算法相似。当我们散列元组时,我们读取 \(R\) 的每一个块一次,并且将每个桶的每个块写到磁盘上。然后在针对各个桶中的一趟算法中,我们再次读取每个桶的每一块。因此,磁盘 \(I/O\) 的总数量是 \(3B( R)\) 。
6.3 基于散列的分组和聚集算法
为了执行 \(\gamma_{L}( R)\) 操作,我们也是首先将 \(R\) 的所有元组散列到 \(M-1\) 个桶中。然而,为了确保同一分组的所有元组最终都在同一个桶内,我们选择的散列函数依赖于表 \(L\) 中的分组属性。
将 \(R\) 分到桶中以后,接下来,我们可以利用之前章节中 \(\gamma\) 的 一趟算法 依次处理每个桶。和我们在上节中对 \(\delta\) 的讨论一样,只要 \(B( R) \leq M^{2}\) ,我们就可以在内存中处理每一个桶。
然而,在第二趟中,我们需要在处理每个桶时仅需要每组一个记录。因此,即使桶的大小大于 \(M\) ,只要桶内所有分组的记录需要的缓冲区数不超过 \(M\) ,我们就可以在一趟算法中处理此桶。因此,如果分组很少,那么我们实际上能处理的关系 \(R\) 可能比 \(B( R)\leq M^{2}\) 规则指出的更大。另一方面,如果 \(M\) 超过了分组的数量,那么,我们不能填充所有的桶。所以,作为 \(M\) 的一个函数, \(R\) 的大小的实际限制很复杂,但 \(B( R)\leq M^{2}\) 是一个保守的估计。最后,和 \(\delta\) 一样,我们观察到 \(\gamma\) 的磁盘 \(I/O\) 数是 \(3B( R)\) 。
6.4 基于散列的并、交、差算法
当操作是二元的时,我们必须保证使用相同的散列函数来散列两个操作对象的元组。例如,为了计算 \(R\cup_{S}S\) ,我们将 \(R\) 和 \(S\) 各自散列到 \(M-1\) 个桶,例如 \(R_{1},R_{2},…,R_{M-1}\) 和 \(S_{1},S_{2},…,S_{M-1}\) 。然后,对于所有的 \(i\) ,我们计算 \(R_{i}\) 和 \(S_{i}\) 的集合并,并且输出结果。注意,如果一个元组 \(t\) 在 \(R\) 和 \(S\) 中都出现,那么对于某 \(i\) ,我们在 \(R_{i}\) 和 \(S_{i}\) 中都将发现 \(t\) 。这样,当我们计算这两个桶的并时,我们将仅输出 \(t\) 的一个副本,不可能将重复引入结果中。对于 \(\cup_{B}\) 而言,之前章节中的 包-并 算法胜于执行这一操作的任何其他方法。
为了计算 \(R\) 和 \(S\) 的交和差,我们像计算集合并时一样创建 \(2(M-1)\) 个桶,并且在每对对应的桶上运用适当的一趟算法。注意,所有这些一趟算法需要 \(B( R)+B(S)\) 次磁盘 \(I/O\) 。在这个数目上,我们还必须加上每个块的两次磁盘 \(I/O\) 。这是用来散列两个关系中的元组并将桶存储到磁盘上,一共是 \(3(B( R) + B(S))\) 次磁盘 \(I/O\) 。
为了使算法可行,我们必须能一趟计算 \(R_{i}\) 和 \(S_{i}\) 的并、交或差, \(R_{i}\) 和 \(S_{i}\) 的大小分别约为 \(B( R)/M-1\) 和 \(B(S)/M-1\) 。回忆一下,这些操作的一趟算法要求较小的操作对象至多占 \(M-1\) 个块。因此,基于散列的两趟算法近似地要求 \(min(B( R), B(S)) \leq M^{2}\) 。
6.5 基于散列的连接算法
为了使用基于散列的两趟算法计算 \(R(X, Y) \bowtie S(Y, Z)\) ,我们要做的与上节讨论其他二元操作几乎一样。唯一区别是我们必须用连接属性 \(Y\) 作为散列关键字。这样我们就能确定,如果 \(R\) 与 \(S\) 的元组能连接,那么它们必然出现在具有某个 \(i\) 值对应的桶 \(R_{i}\) 和 \(S_{i}\) 中。所有对应桶对的一个一趟连接最后完成这个我们称为 散列连接 算法。
样例
让我们再次假定两个关系 \(R\) 和 \(S\) ,它们的大小分别为 \(1000\) 块和 \(500\) 块,并且有 \(101\) 个内存缓冲区是可用的。我们将每一个关系散列到 \(100\) 个桶中,所以一个桶的平均大小对于 \(R\) 是 \(10\) 个块,对于 \(S\) 是 \(5\) 个块。因为较小的数 \(5\) 远远小于可得到的缓冲区的数量,我们预计在每一对桶 \(i\) 上执行一趟连接不会有困难。
当散列到桶中时,读取 \(R\) 和 \(S\) 共需要 \(1500\) 次磁盘 \(I/O\) ,将所有的桶写到磁盘又需要 \(1500\) 次,执行对应桶 \(i\) 的一趟连接时再次将每一个对桶 \(i\) 读到内存需要第三个 \(1500\) 。因此,需要的磁盘 \(I/O\) 是 \(4500\) ,和之前章节中高效的排序连接一样。
我们对样例进行推导而得出如下结论:
- 散列连接需要 \(3(B( R) + B(S))\) 次磁盘 \(I/O\) 来完成它的任务。
- 只要近似地有 \(min(B( R), B(S)) \leq M^{2}\) ,两趟散列连接算法就是可行的。
后一点的操作对象与其他二元操作相同: 每一对桶 \(i\) 中必须有一个能全部装入 \(M-1\) 个缓冲区中。
6.6 节省一些磁盘 \(I/O\)
TODO…